
👋 About Me
I am pursuing my Ph.D. from the Institute of Computing Technology  , Chinese Academy of Sciences
, Chinese Academy of Sciences  , advised by Prof. Zhaoqi Wang. I am also a Research Intern at LongCat Team, Meituan
, advised by Prof. Zhaoqi Wang. I am also a Research Intern at LongCat Team, Meituan  . Previously, I was a Research Intern at DreamX-World Team, Alibaba
. Previously, I was a Research Intern at DreamX-World Team, Alibaba  . I am deeply grateful for the opportunity to collaborate with exceptional researchers including Prof. Shuo Li, Prof. Yujun Cai, and Prof. Yiwei Wang. Their mentorship and insights have profoundly shaped my academic journey.
. I am deeply grateful for the opportunity to collaborate with exceptional researchers including Prof. Shuo Li, Prof. Yujun Cai, and Prof. Yiwei Wang. Their mentorship and insights have profoundly shaped my academic journey.
My research interests include Vision-Language Model, Agentic Reinforcement Learning, Spatial Intelligence, Foundation Model, Embodied Agents, etc. I have published 30+ papers at top international AI conferences such as NeurIPS, ICLR, ICML, CVPR, ICCV, AAAI, etc.
🎯 Research Areas
🔥 Main News
- 2026.05 🎉 Our work Reasoning-VLA has been Accepted by ICML 2026.
- 2026.01 💼 Joined LongCat Team, Meituan as a Beidou Talent Program Intern, working on the M17 3A Base Model team.
- 2026.02 🎉 Our work ADE-CoT has been Accepted by CVPR 2026.
- 2026.01 🎉 Our work Video-STAR has been Accepted by ICLR 2026.
- 2026.01 🎉 Our work AutoDrive-R² has been Accepted by ICLR 2026.
- 2025.10 🎉 Our work DVP-MVS++ has been Accepted by TCSVT 2025.
- 2025.08 🎉 Our work AutoDrive-R² was reported by AutoDrive Heart (自动驾驶之心).
- 2025.05 💼 Joined DreamX-World Team, Alibaba as a Research Intern.
- 2025.05 🎉 Our work SED-MVS has been Accepted by TCSVT 2025.
- 2024.12 🎉 Our work DVP-MVS has been Accepted by AAAI 2025.
- 2024.12 🎉 Our work MSP-MVS has been Accepted by AAAI 2025.
- 2024.05 🎉 Our work TSAR-MVS has been Accepted by PR 2024.
- 2023.12 🎉 Our work SD-MVS has been Accepted by AAAI 2024.
🎓 Education
🎓 Academic Background

Institute of Computing Technology, Chinese Academy of Sciences
Ph.D. in Information and Communication Engineering
📍 Beijing · Sep 2021 - Present
- Research focus: Vision-Language Models, Large Language Models, Embodied Agents, Multimodal AI, 3D Vision
- Advised by Prof. Zhaoqi Wang
- Collaborated with Prof. Shuo Li, Prof. Yujun Cai, and Prof. Yiwei Wang
- Published 20+ papers at top AI conferences including NeurIPS, ICLR, ICML, CVPR, ICCV, AAAI
💼 Professional Experience
💼 Industry Experience

DreamX-World Team, Alibaba
Research Intern
📍 Beijing · Jun 2025 - Jan 2026
- Research focus: Vision-Language Models, Foundation Models, Agentic AI
- Official GitHub: AMAP-ML/DreamX-World
- Previous work: Video-STAR, AutoDrive-R², Reasoning-VLA

LongCat Team, Meituan
Beidou Talent Program Intern, M17 3A Base Model Team
📍 Beijing · Feb 2026 - Present
- LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal inductive bias beyond the language paradigm.
- Contributing to the M173A foundation model research and development
📝 Selected Publications
For a complete list of publications, please visit my Google Scholar profile
Note: * denotes equal contribution
📄 Technical Report 1
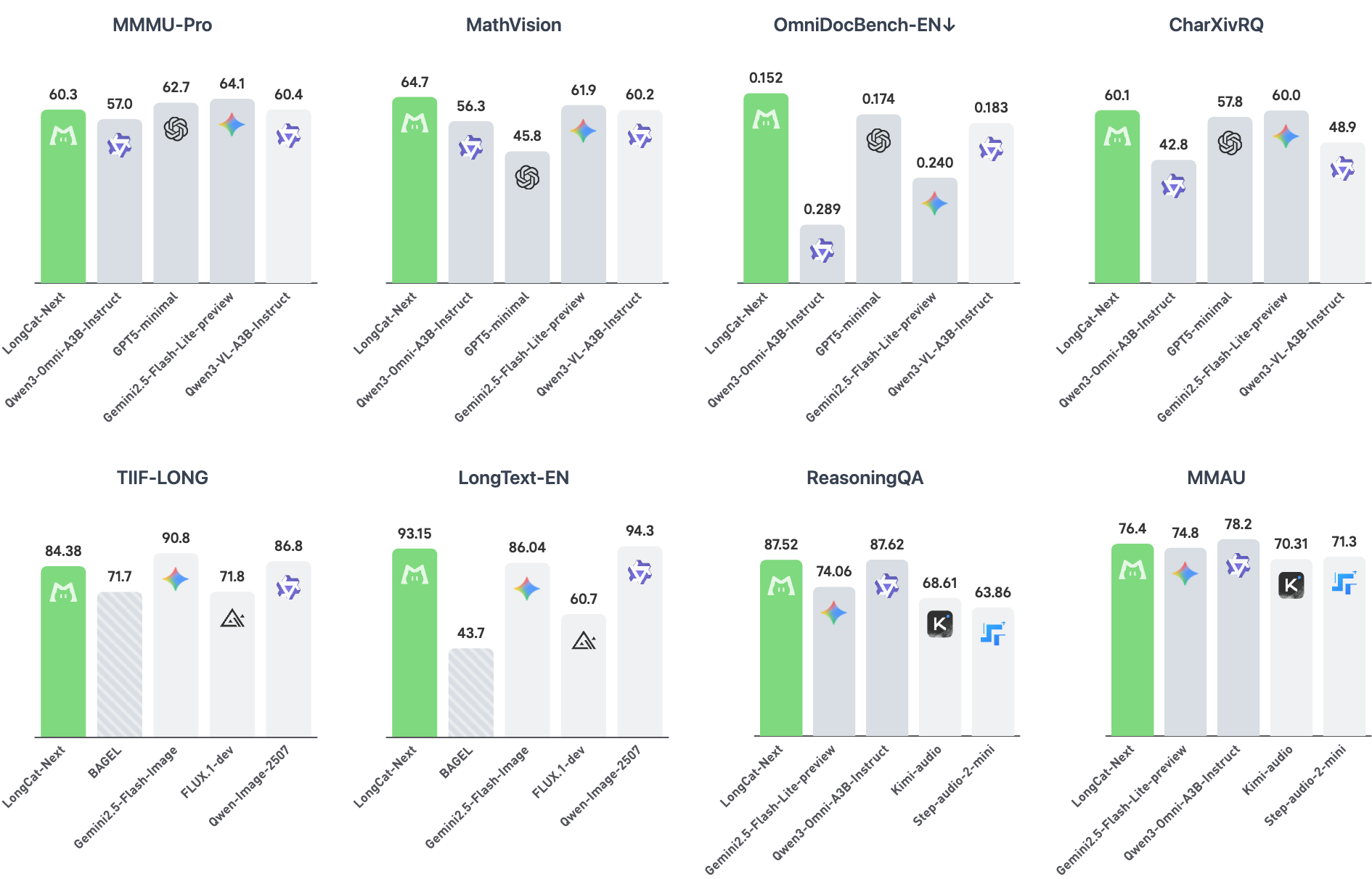
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Native Multimodal
Any-to-Any Generation
Foundation Model
Meituan LongCat Team
LongCat-Next is a native multimodal model (A3B) that unifies text, vision, and audio under a single autoregressive objective via discrete tokenization, achieving strong performance across multimodal benchmarks.
🤖 Vision-Language Models & VLA 4
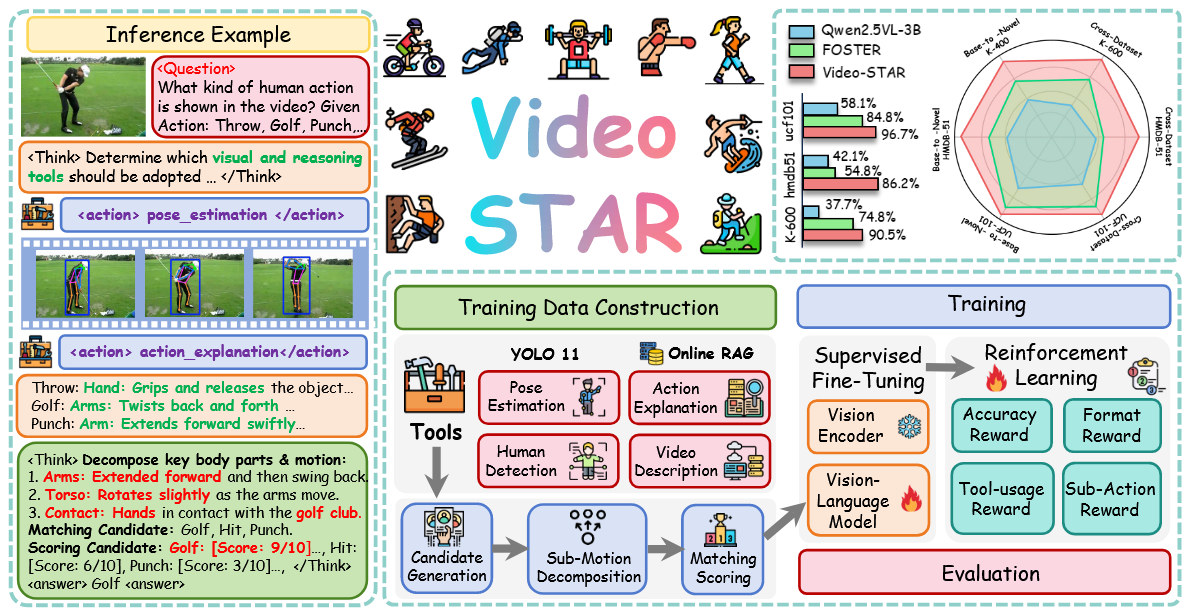
Video-STAR: Reinforcing Zero-shot Video Understanding with Tools
Tool-Using Agent
Multi-turn RL
Zero-shot Video
Yuan Z., Qu X., Qian, C., Chen, R., Tang, J., Sun L., Chu X., Zhang D., Wang Y., Cai Y., Li S.
Video-STAR proposes a novel framework that reinforces zero-shot video understanding through tool-use agents with multi-turn reasoning.
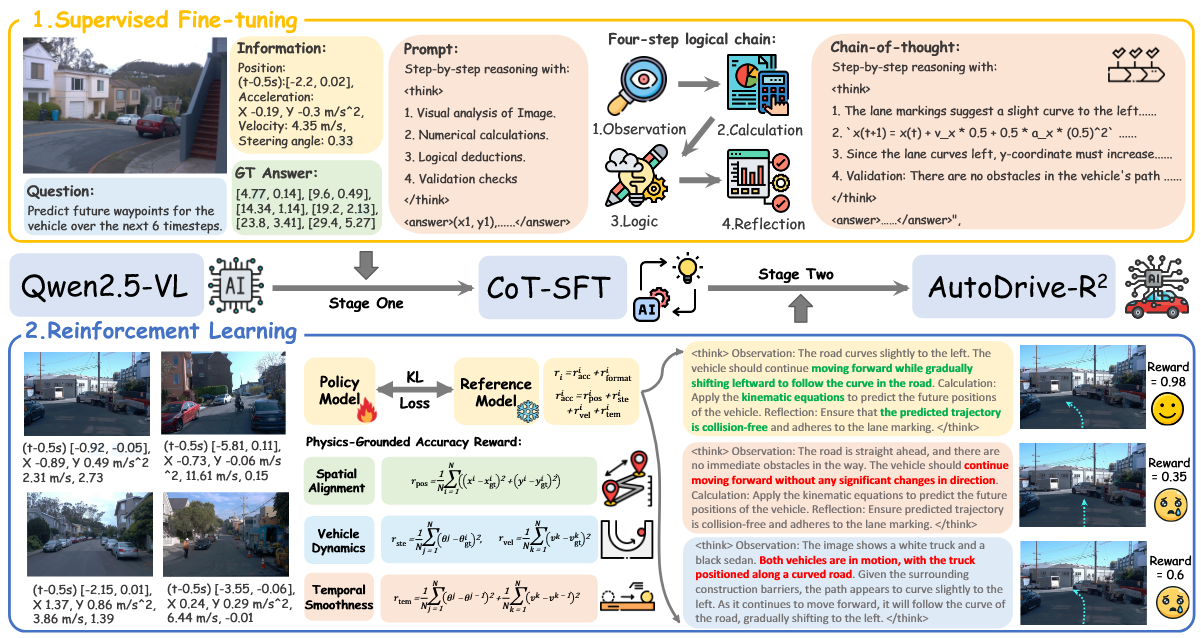
AutoDrive-R²: Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving
Multimodal Reasoning
Autonomous Driving
Vision-Language-Action
Featured by AutoDrive Heart (自动驾驶之心)
Yuan Z., Tang, J., Luo, J., Chen, R., Qian, C., Sun, L., Cai Y., Zhang D., Li, S.
AutoDrive-R² introduces a reasoning and self-reflection framework for Vision-Language-Action models in autonomous driving scenarios.
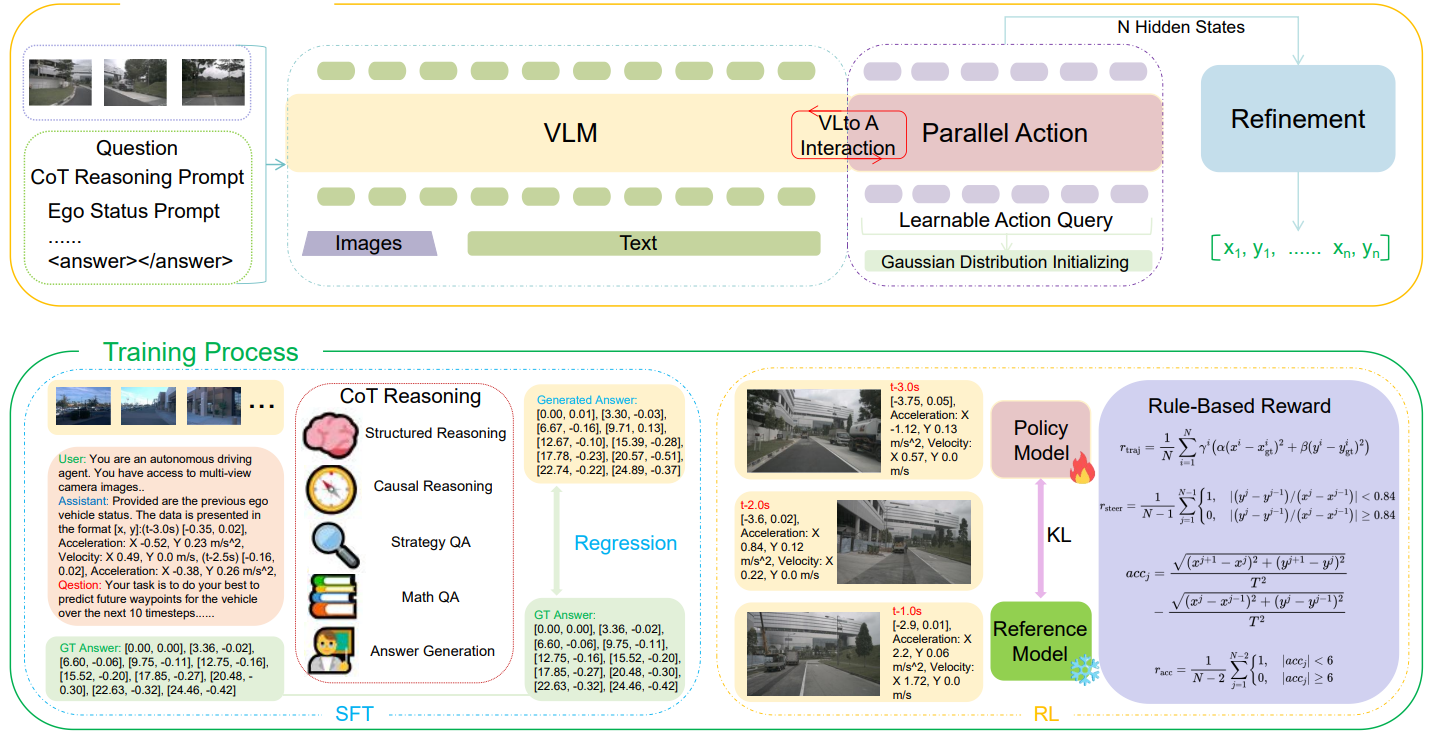
Reasoning-VLA: A Fast and General Vision-Language-Action Reasoning Model for Autonomous Driving
Autonomous Driving
Fast VLA
Real-time Inference
Zhang D.*, Yuan Z.*, Chen Z., Liao C., Chen Y., Shen F., Zhou Q., Chua T.
Reasoning-VLA presents a fast and general VLA reasoning model optimized for real-time autonomous driving applications.
🎨 Generative Foundation Model 2
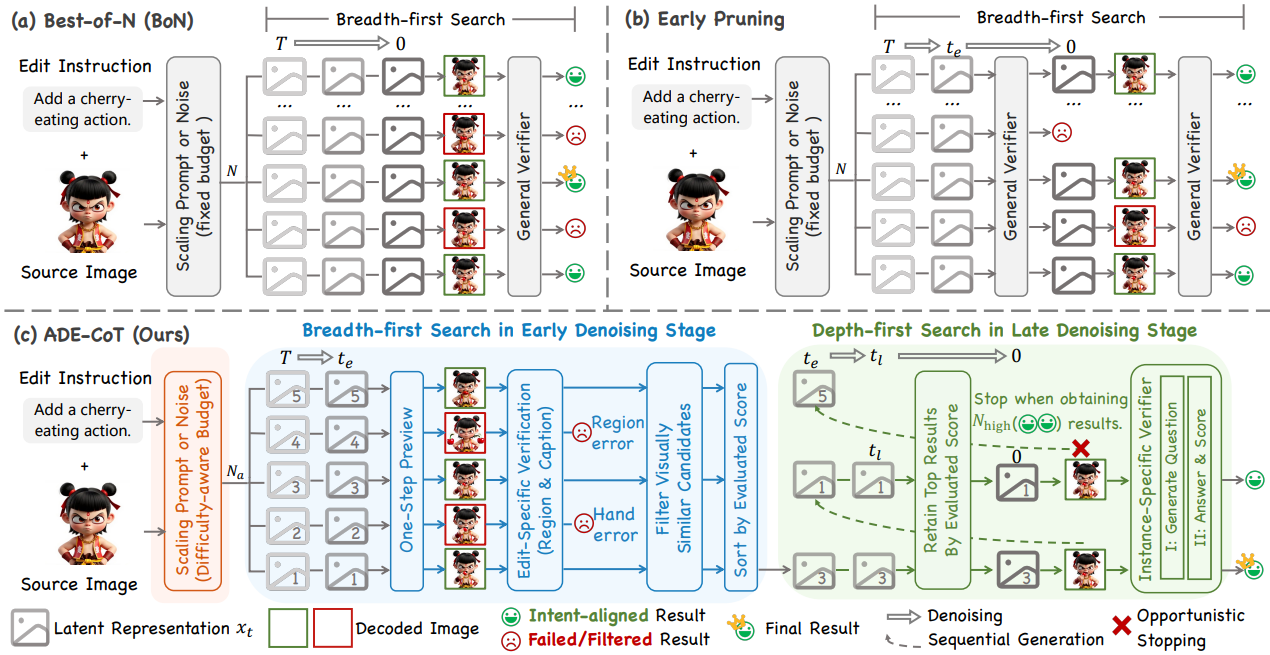
ADE-CoT: Adaptive Diffusion Elicits Chain-of-Thought in Image Editing
Diffusion Model
Chain-of-Thought
Image Editing
Qu X.*, Yuan Z.*, Tang J., Chen R., Tang D., Yu M., Sun L., Bai Y., Chu X., Gou G., Xiong G., Cai Y.
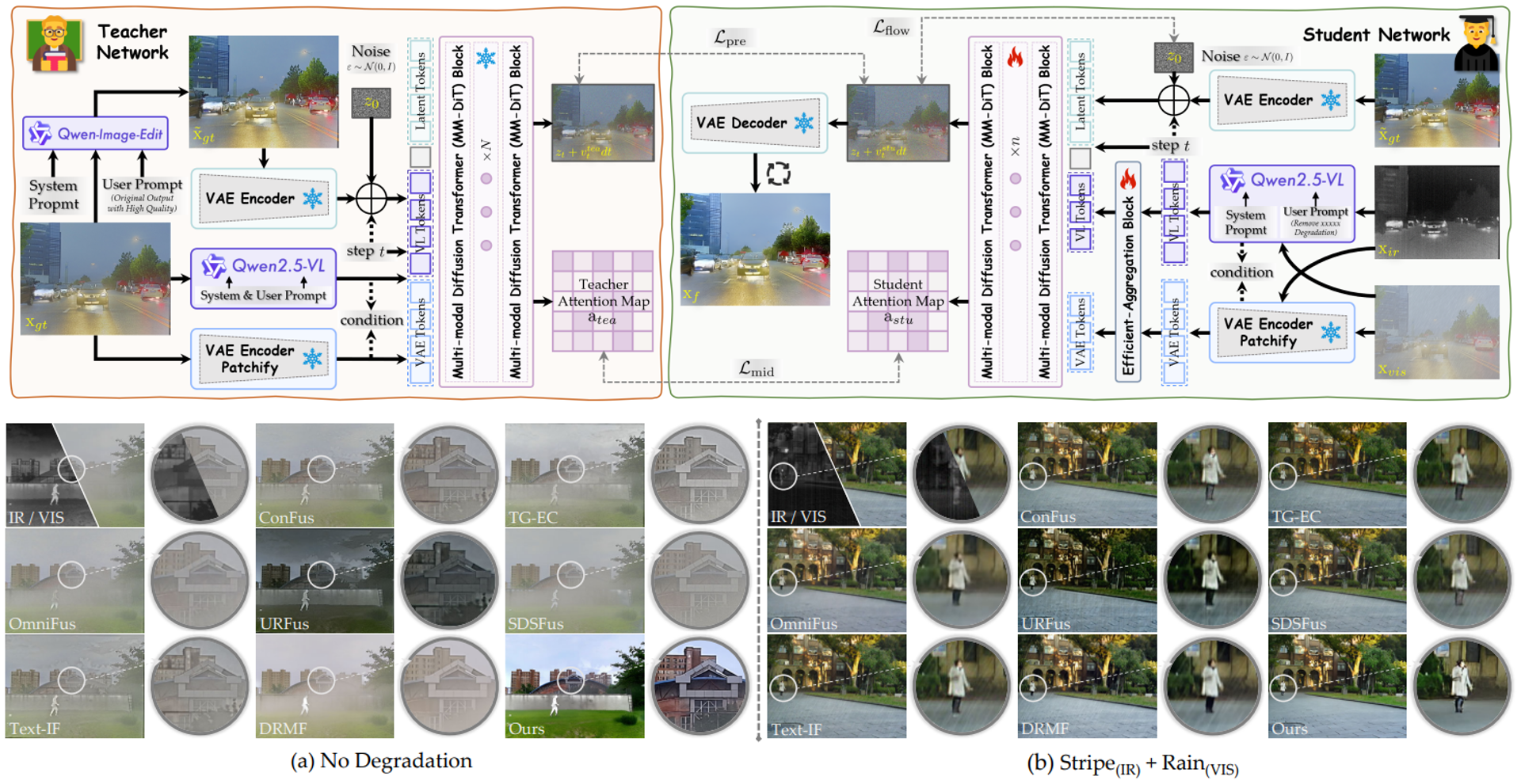
Recovering Degradations with Generative Model: A Consistency-aware Distillation Network for Infrared and Visible Image Fusion
Generation Model
Image Fusion
Infrared-Visible
Yu H.*, Yuan Z.*, Bai Y., Li J., Liu J., Li S., Sun L., Chu X.
📐 3D Vision 6
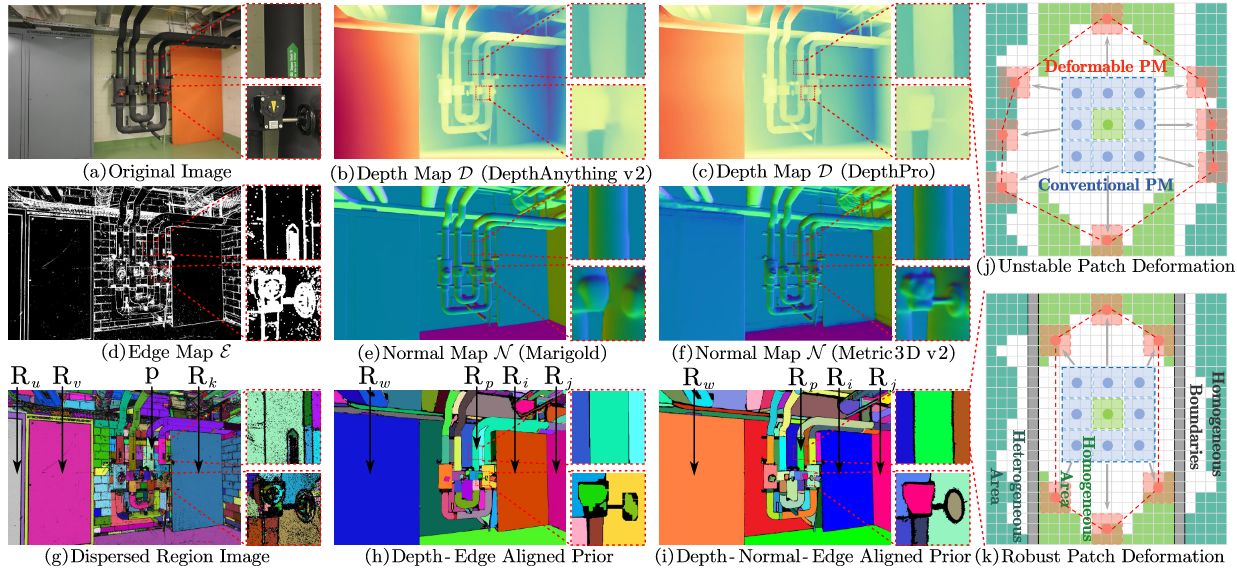
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Multi-View Stereo
3D Reconstruction
Yuan Z., Zhang, D., Li, Z., Qian, C., Chen, J., Chen, Y., Chen K., Mao T., Li Z., Jiang H., Wang, Z.
DVP-MVS++ advances multi-view stereo through synergistic depth-normal-edge and visibility prior modeling.
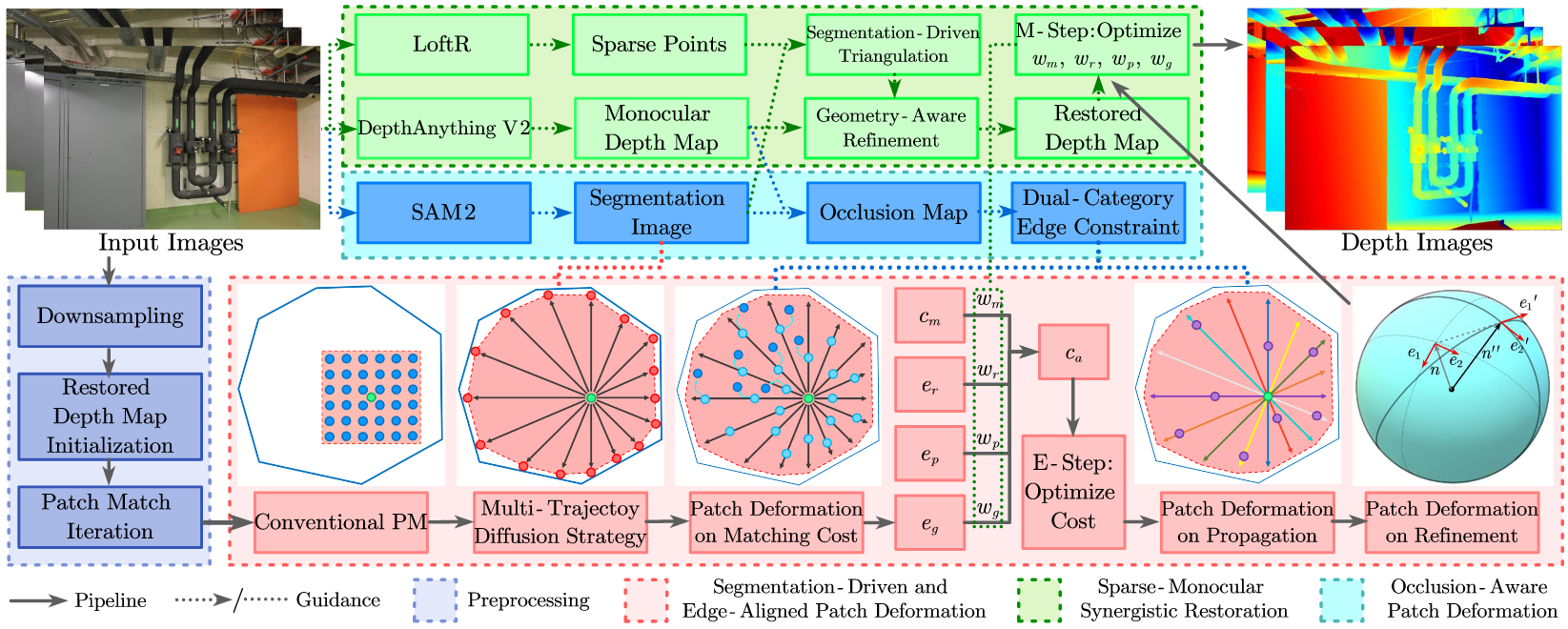
SED-MVS: Segmentation-Driven and Edge-Aligned Deformation Multi-View Stereo with Depth Restoration and Occlusion Constraint
Segmentation-Driven
Depth Estimation
Yuan Z., Yang, Z., Cai, Y., Wu, K., Liu, M., Zhang, D., Jiang H, Li Z., Wang, Z.
SED-MVS introduces segmentation-driven and edge-aligned deformation for robust multi-view stereo with depth restoration.
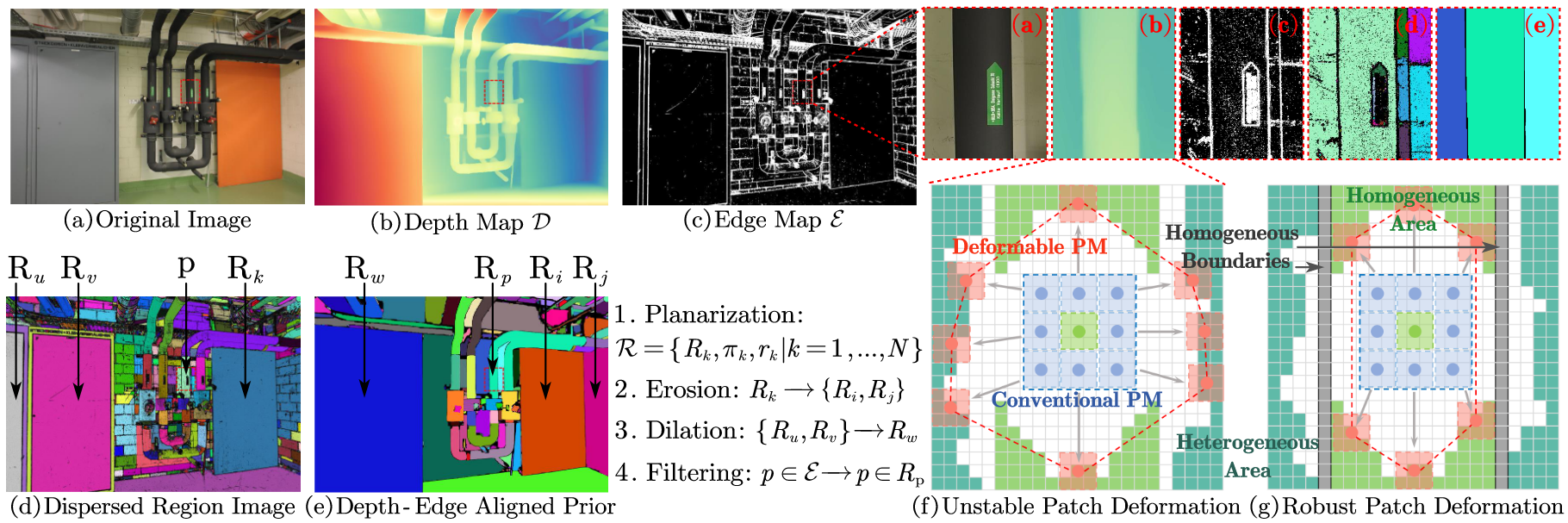
DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo
Visibility Prior
3D Vision
Yuan Z., Luo, J., Shen, F., Li, Z., Liu, C., Mao, T., Wang, Z.
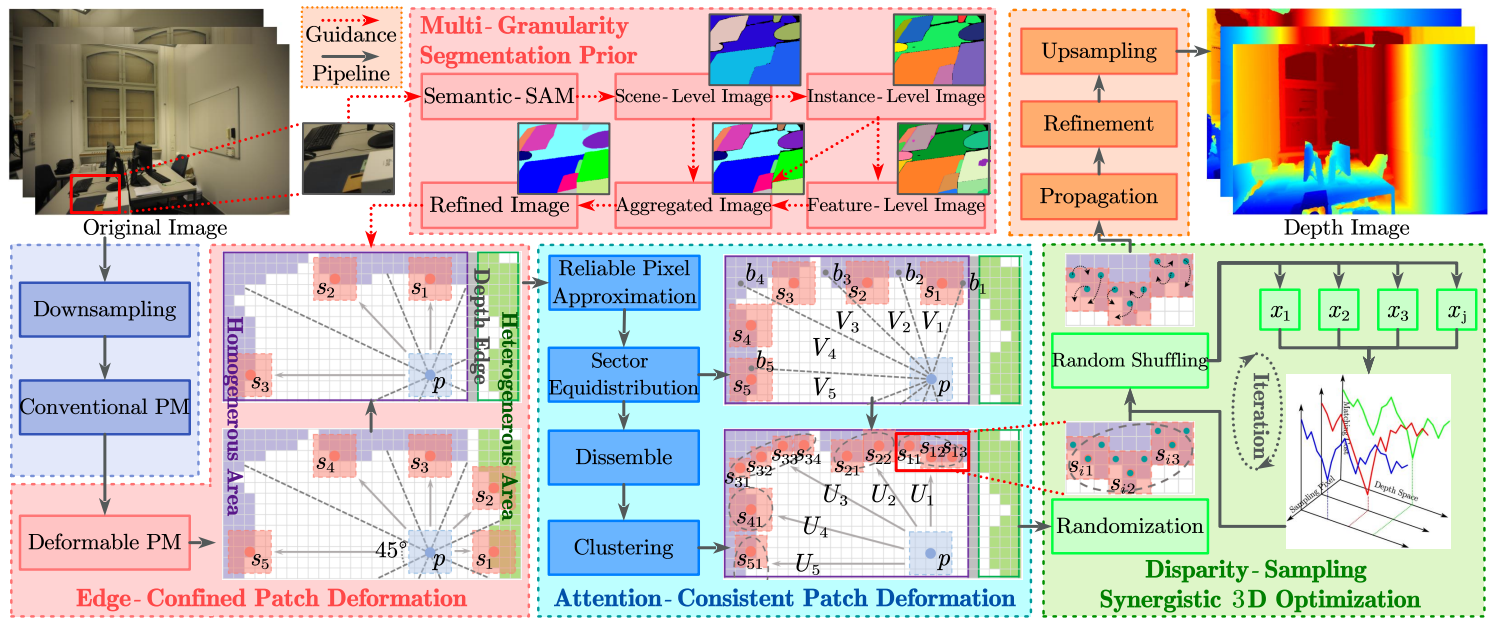
MSP-MVS: Multi-granularity segmentation prior guided multi-view stereo
Segmentation Prior
Multi-View
Yuan Z., Liu, C., Shen, F., Li, Z., Luo, J., Mao, T., Wang, Z.
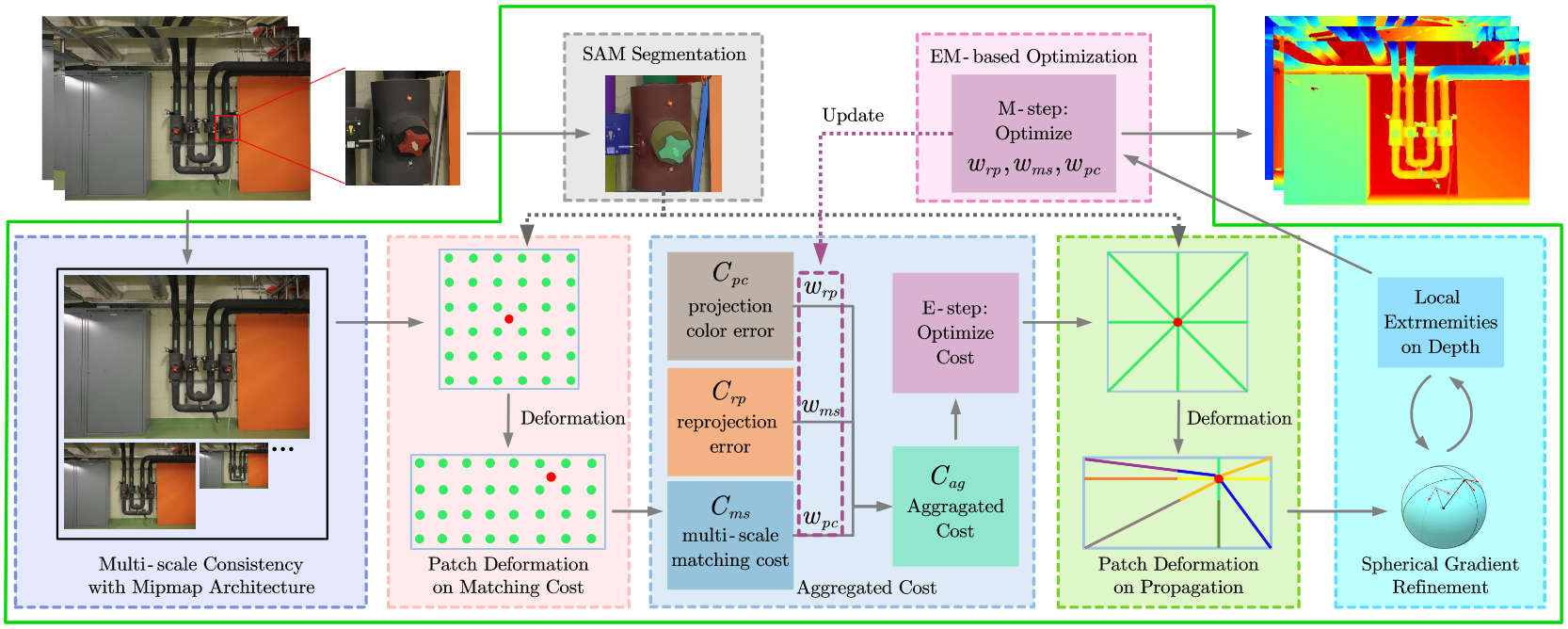
SD-MVS: Segmentation-driven deformation multi-view stereo with spherical refinement and em optimization
Spherical Refinement
EM Optimization
Yuan Z., Cao, J., Li, Z., Jiang, H., Wang, Z.
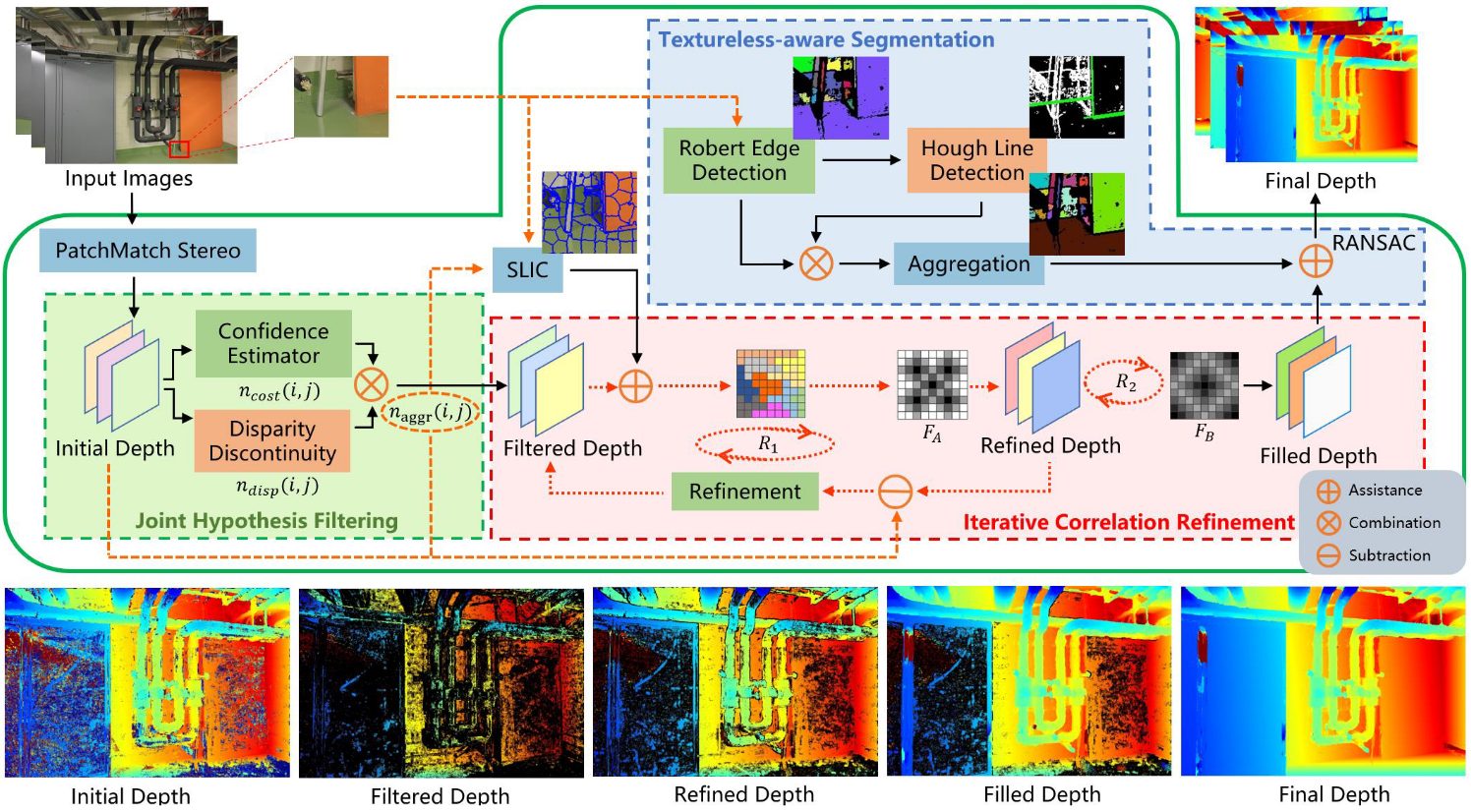
TSAR-MVS: Textureless-Aware Segmentation and Correlative Refinement Guided Multi-View Stereo
Textureless-Aware
3D Vision
Yuan Z., Cao, J., Wang, Z., Li, Z.
🎓 Professional Service
🎓 Professional Service
📬 Let's Connect
📫 Email: yuanzhenlong.yzl@gmail.com
💼 I'm eager to connect with fellow AI researchers and enthusiasts passionate about advancing multimodal AI and embodied intelligence.
📍 Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China