
👋 About Me
I am currently pursuing my Ph.D. at the Institute of Computing Technology  , Chinese Academy of Sciences
, Chinese Academy of Sciences  , advised by Prof. Zhaoqi Wang. Concurrently, I serve as a Research Intern at AMAP
, advised by Prof. Zhaoqi Wang. Concurrently, I serve as a Research Intern at AMAP  , Alibaba
, Alibaba  , where I work closely with Xiangxiang Chu. I am deeply grateful for the opportunity to collaborate with exceptional researchers including Prof. Shuo Li, Prof. Yujun Cai, and Prof. Yiwei Wang. Their mentorship and insights have profoundly shaped my academic journey.
, where I work closely with Xiangxiang Chu. I am deeply grateful for the opportunity to collaborate with exceptional researchers including Prof. Shuo Li, Prof. Yujun Cai, and Prof. Yiwei Wang. Their mentorship and insights have profoundly shaped my academic journey.
My research interest includes Vision-Language Model (VLM), Large Language Model (LLM), Embodied Agents, Multimodal AI, and 3D Vision. I have published 20+ papers at the top international AI conferences such as NeurIPS, ICLR, ICML, CVPR, ICCV, AAAI, etc.
📚 Research Interests
- Foundation Models & Pre-training 🔥🔥
- Vision-Language Models (VLMs) / Vision-Language Action (VLA) / Spatial Intelligence
- Model Enhancement & Post-training 🔥🔥
- Reasoning & Alignment / Tool-Augmented RL / NLP-Enhanced Training
- Model Interpretation 🔥🔥
- Mechanistic Interpretability / Factuality, Truthfulness, and Social Good
- Real-World Applications🔥🔥
- Embodied Agents / AI for Science / Biomedical Engineering
🔥 Main News
- 2026.02: 🎉🎉 Our work ADE-CoT has been Accepted by CVPR 2026.
- 2026.01: 🎉🎉 Our work Video-STAR has been Accepted by ICLR 2026.
- 2026.01: 🎉🎉 Our work AutoDrive-R² has been Accepted by ICLR 2026.
- 2025.11: 🎉🎉 We propose ADE-CoT, which is now available on ArXiv!
- 2025.11: 🎉🎉 We propose Reasoning-VLA, which is now available on ArXiv!
- 2025.10: 🎉🎉 Our work DVP-MVS++ has been Accepted by TCSVT 2025.
- 2025.10: 🎉🎉 We propose Video-STAR, which is now available on ArXiv!
- 2025.08: 🎉🎉 Our work AutoDrive-R² was reported by AutoDrive Heart (自动驾驶之心)
- 2025.08: 🎉🎉 We propose AutoDrive-R², which is now available on ArXiv!
- 2025.06: 🎉🎉 We propose DVP-MVS++, which is now available on ArXiv!
- 2025.05: 🎉🎉 Our work SED-MVS has been Accepted by TCSVT 2025.
- 2024.12: 🎉🎉 We propose SED-MVS, which is now available on ArXiv!
- 2024.12: 🎉🎉 Our work DVP-MVS has been Accepted by AAAI 2025.
- 2024.12: 🎉🎉 Our work MSP-MVS has been Accepted by AAAI 2025.
- 2024.08: 🎉🎉 We propose DVP-MVS, which is now available on ArXiv!
- 2024.08: 🎉🎉 We propose MSP-MVS, which is now available on ArXiv!
- 2024.05: 🎉🎉 Our work TSAR-MVS has been Accepted by PR 2024.
- 2024.01: 🎉🎉 We propose TSAR-MVS, which is now available on ArXiv!
- 2023.12: 🎉🎉 Our work SD-MVS has been Accepted by AAAI 2024.
- 2023.09: 🎉🎉 We propose SD-MVS, which is now available on ArXiv!
📝 Main Publications
Multimodal LLMs Post-Training
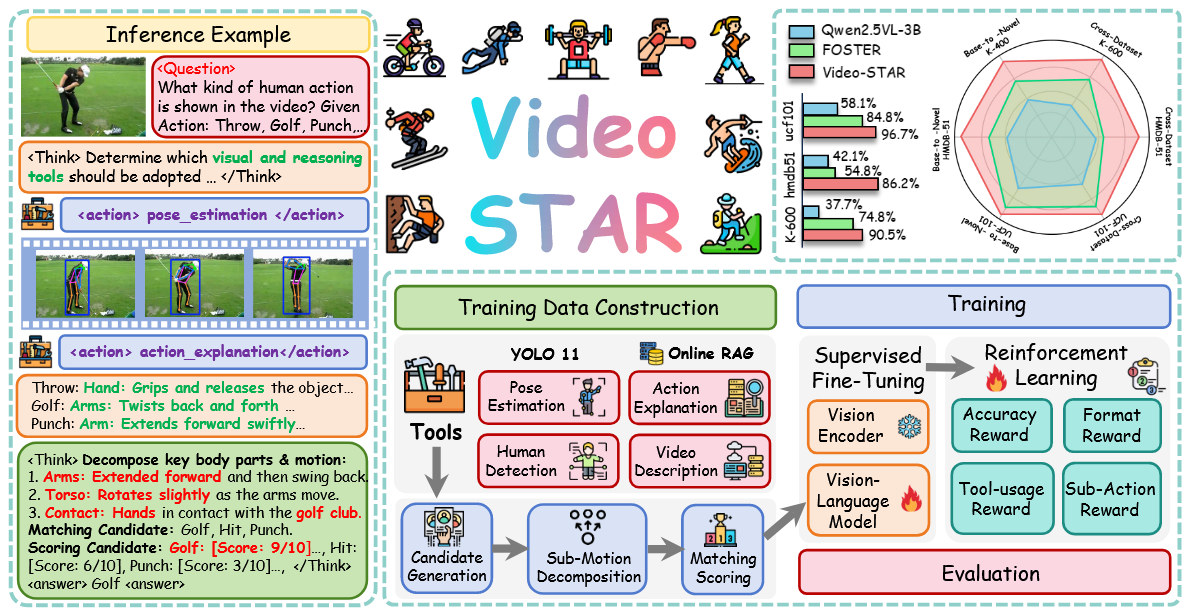
Video-STAR: Reinforcing Zero-shot Video Understanding with Tools
Think with Videos Tool-Using Agent Multi-turn Agentic RL
Yuan Z., Qu X., Qian, C., Chen, R., Tang, J., Sun L., Chu X., Zhang D., Wang Y., Cai Y., Li S.
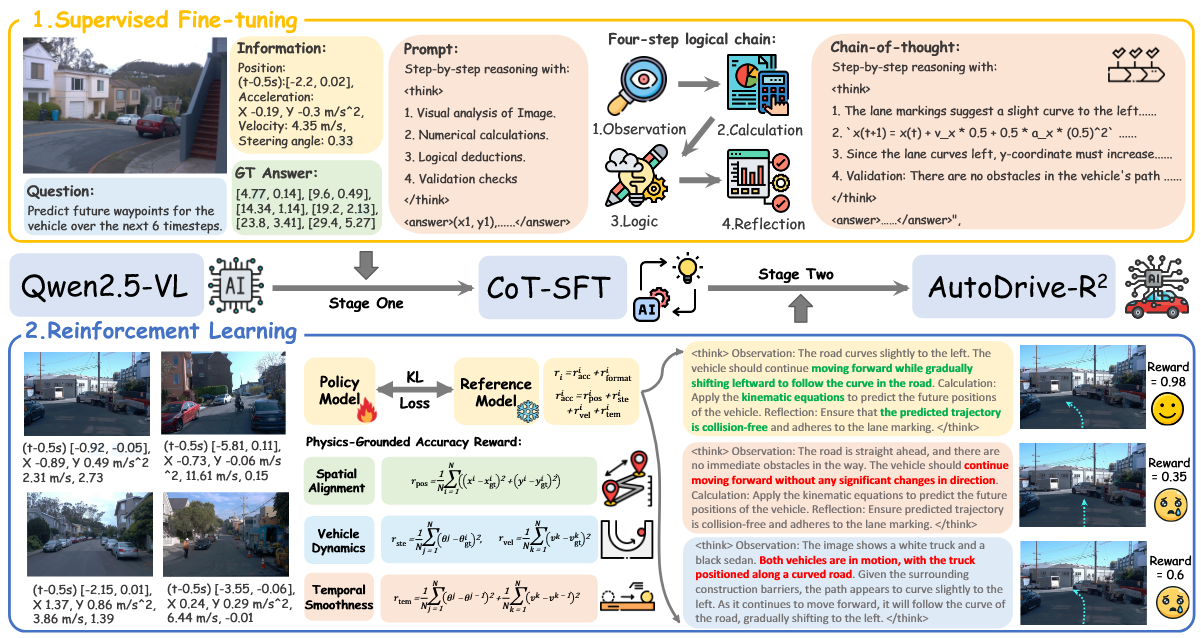
Multimodal Reasoning Autonomous Driving Open-World Applications
Featured by AutoDrive Heart (自动驾驶之心)
Yuan Z., Tang, J., Luo, J., Chen, R., Qian, C., Sun, L., Cai Y., Zhang D., Li, S
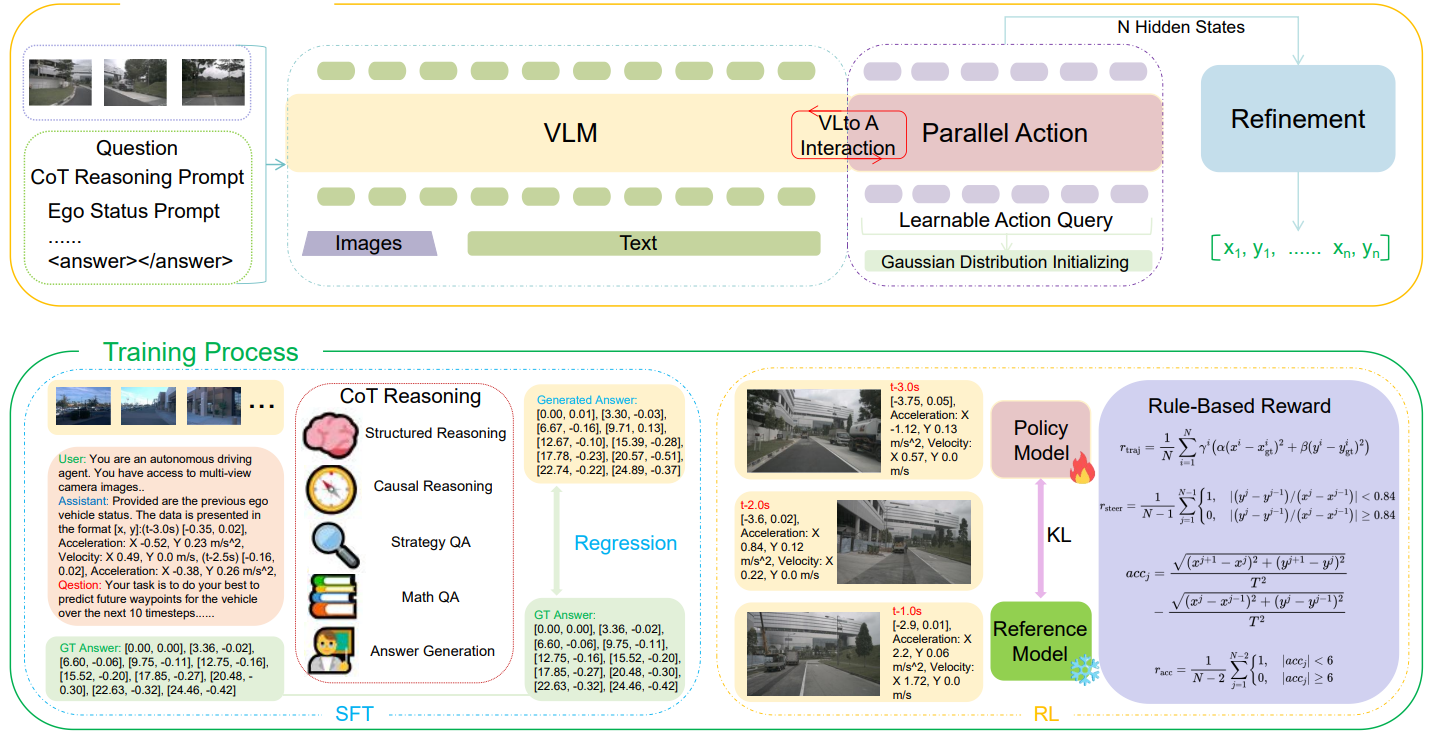
Reasoning-VLA: A Fast and General Vision-Language-Action Reasoning Model for Autonomous Driving
Multimodal Reasoning Autonomous Driving Open-World Applications
Zhang D.*, Yuan Z.*, Chen Z., Liao C., Chen Y., Shen F., Zhou Q., Chua T.
Generative Foundation Model
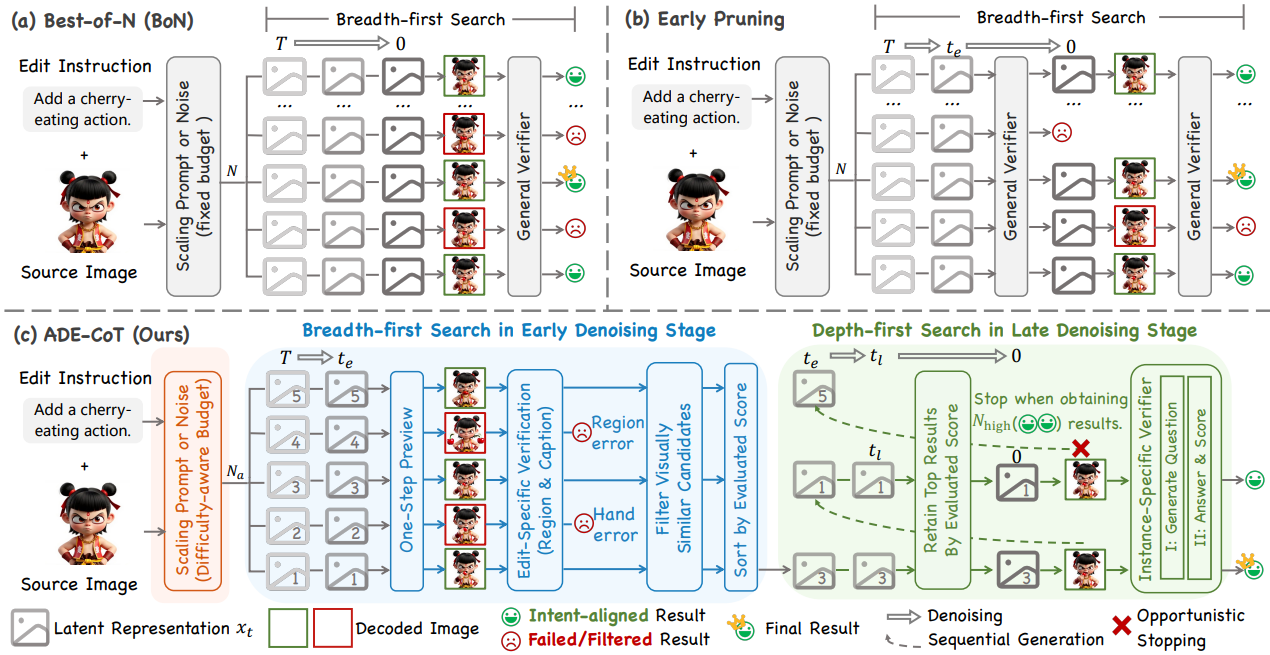
From Scale to Speed: Adaptive Test-Time Scaling for Image Editing
Generation Model Image Editing Text-to-Image Generation
Qu X.*, Yuan Z.*, Tang J., Chen R., Tang D., Yu M., Sun L., Bai Y., Chu X., Gou G,., Xiong G., Cai Y.
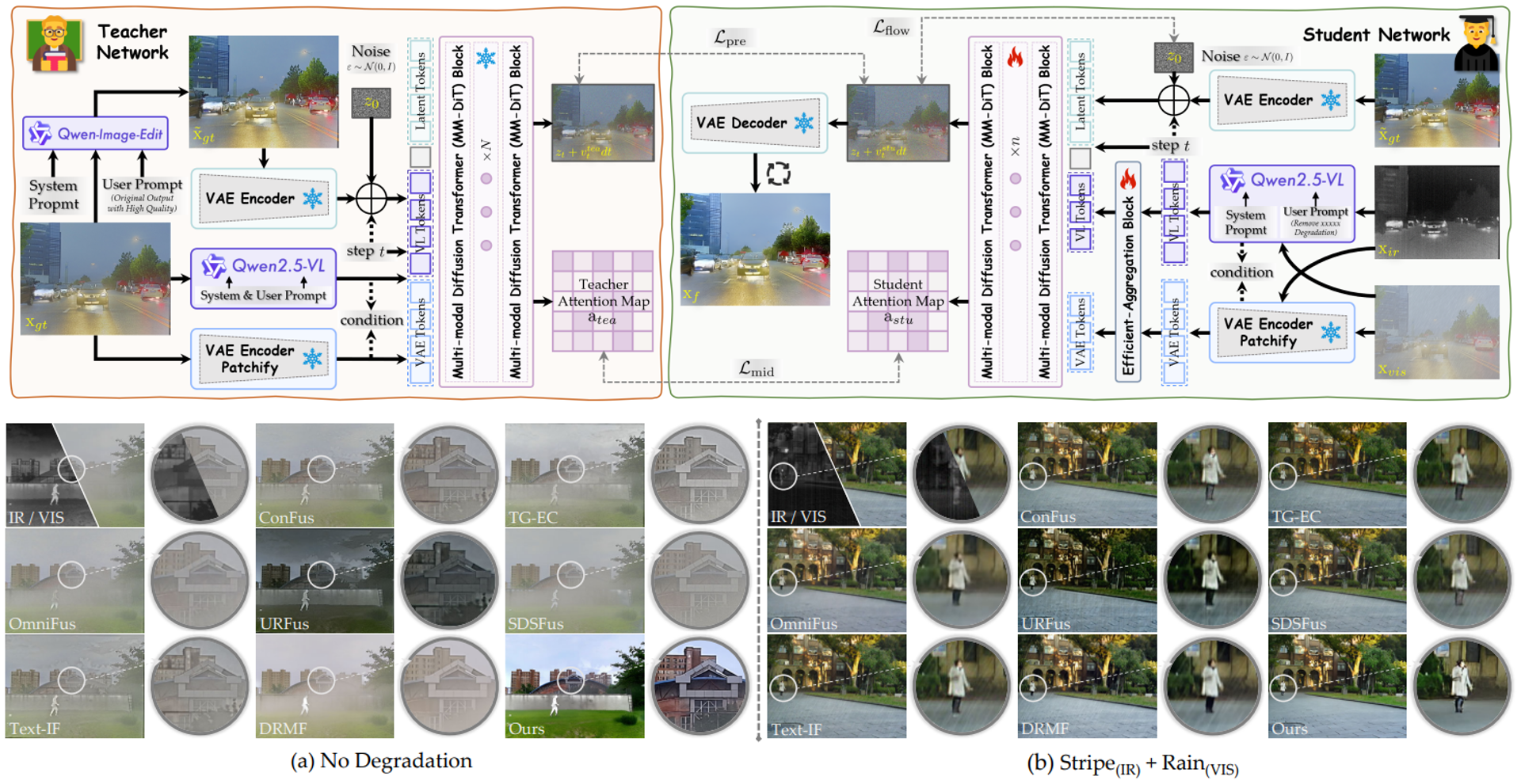
Recovering Degradations with Generative Model: A Consistency-aware Distillation Network for Infrared and Visible Image Fusion
Generation Model Image Editing Text-to-Image Generation
Yu H.*, Yuan Z.*, Bai Y., Li J., Liu J., Li S., Sun L., Chu X.
3D Vision
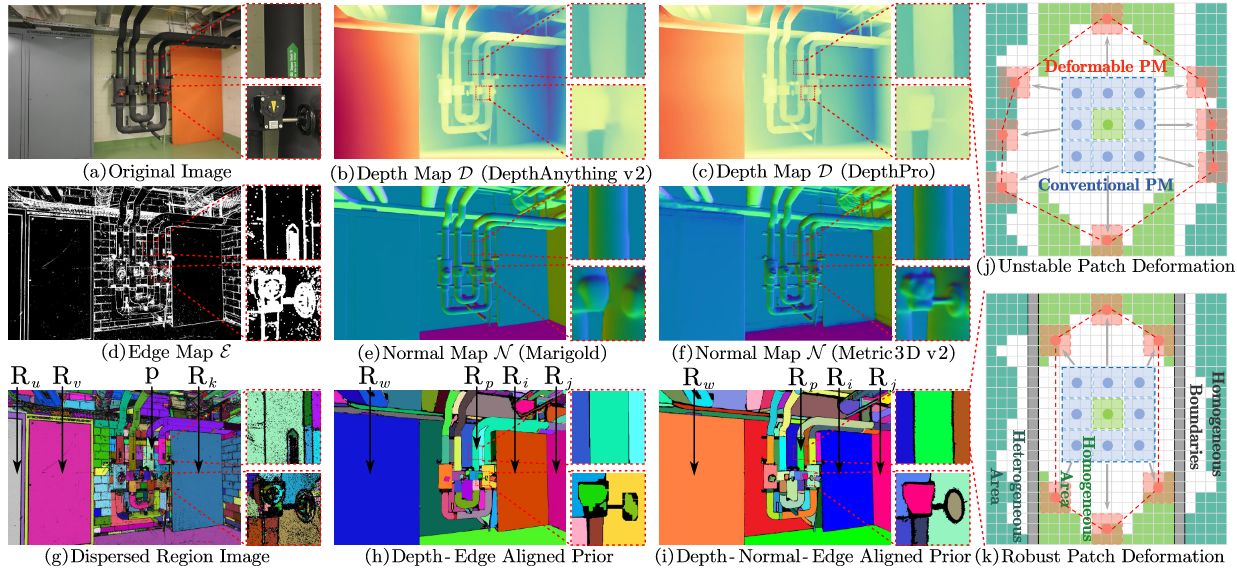
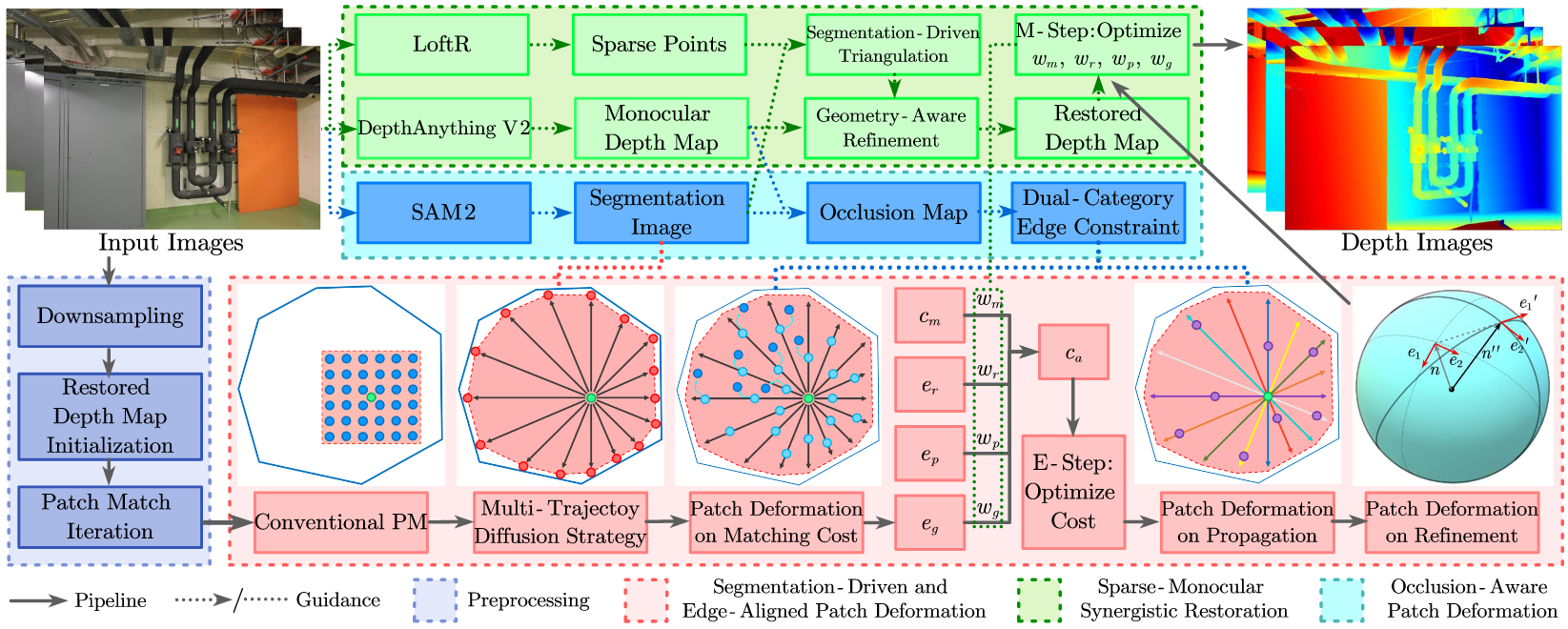
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Yuan Z., Zhang, D., Li, Z., Qian, C., Chen, J., Chen, Y., Chen K., Mao T., Li Z, Jiang H., Wang, Z
IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT) (Under Review), 2025.
Yuan Z.., Yang, Z., Cai, Y., Wu, K., Liu, M., Zhang, D., Jiang H, Li Z., Wang, Z.
IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT), 2025.
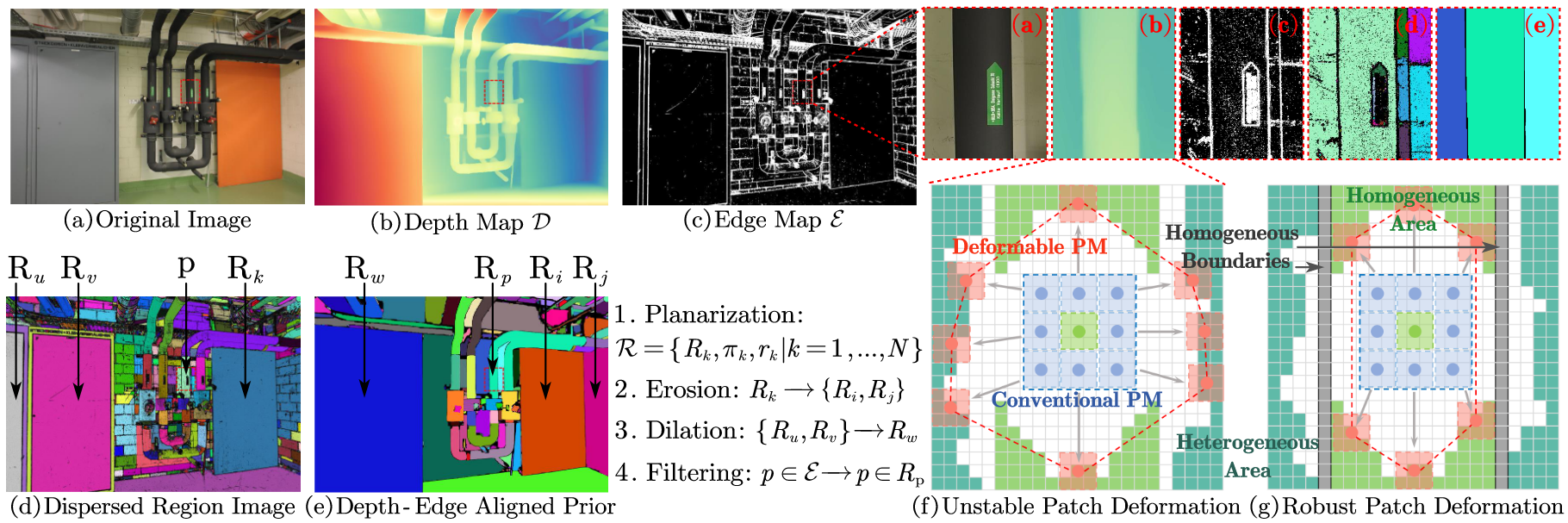
DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo
Yuan Z.., Luo, J., Shen, F., Li, Z., Liu, C., Mao, T., Wang, Z.
AAAI Conference on Artificial Intelligence (AAAI), 2025.
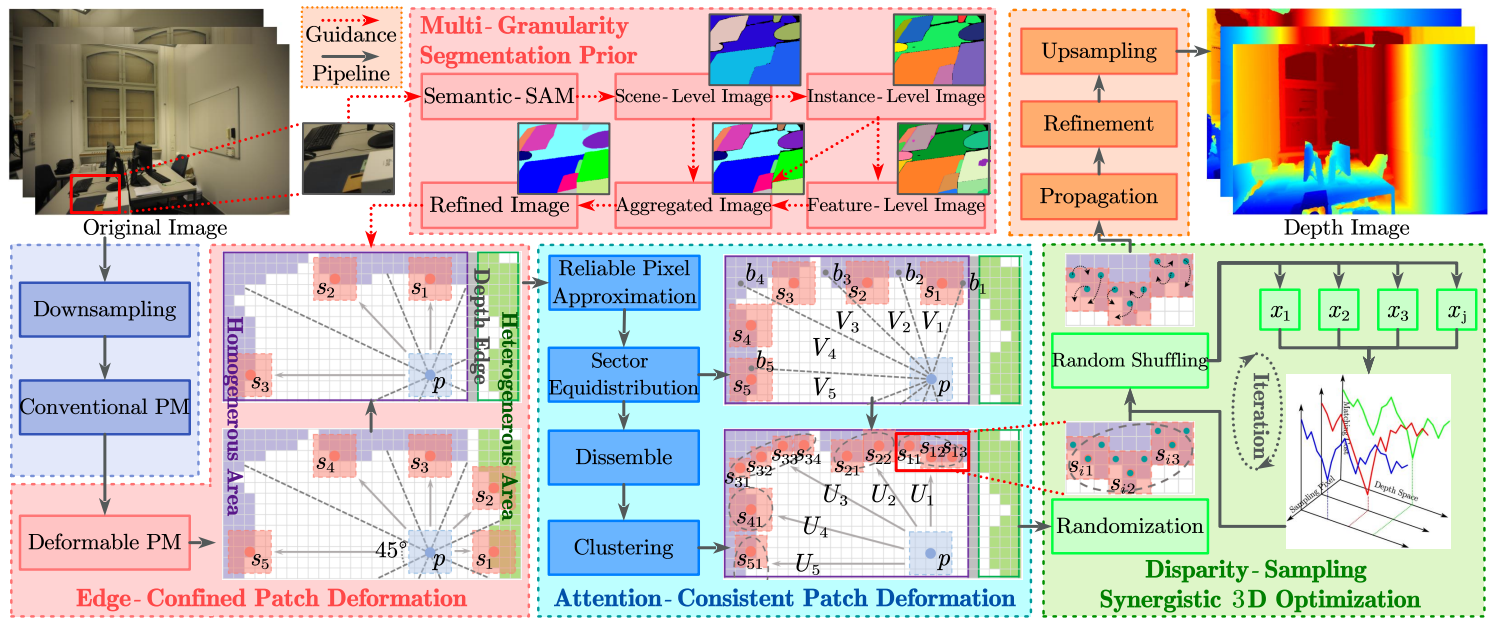
MSP-MVS: Multi-granularity segmentation prior guided multi-view stereo
Yuan Z., Liu, C., Shen, F., Li, Z., Luo, J., Mao, T., Wang, Z.
AAAI Conference on Artificial Intelligence (AAAI), 2025.
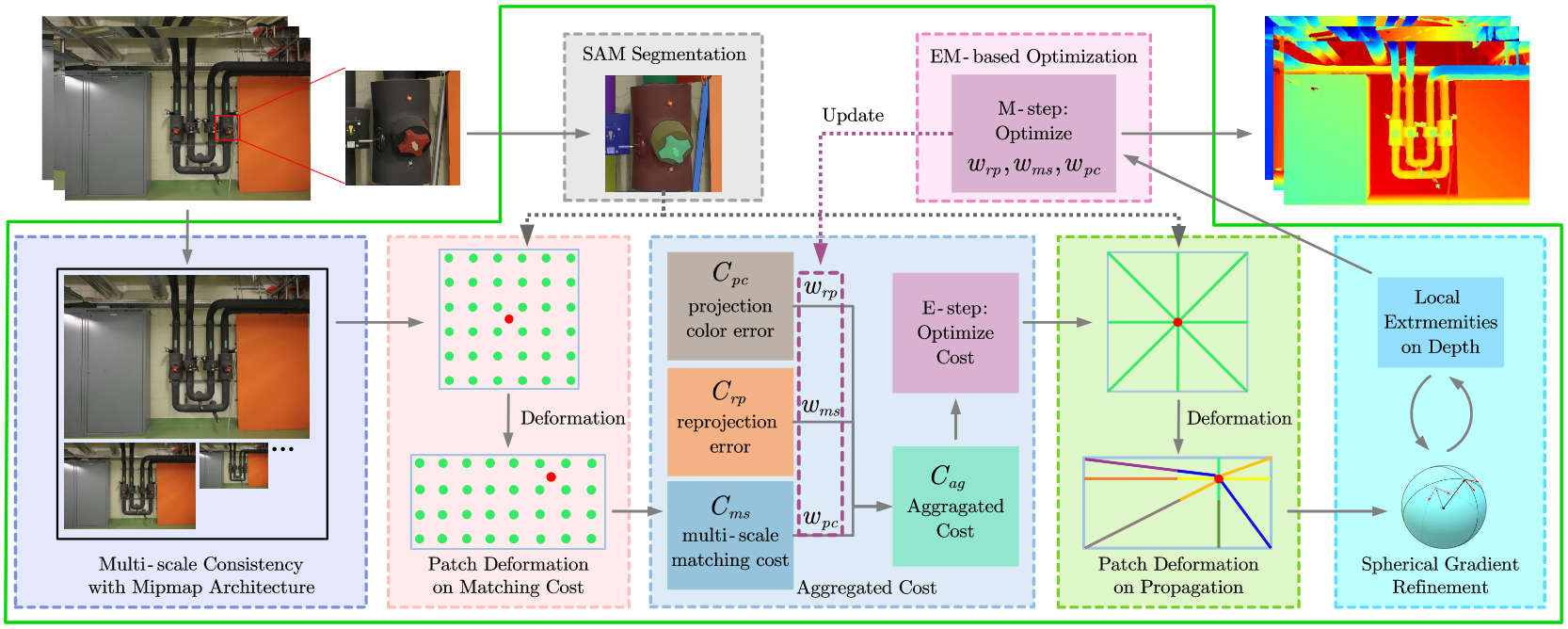
Yuan Z., Cao, J., Li, Z., Jiang, H., Wang, Z.
AAAI Conference on Artificial Intelligence (AAAI), 2024.
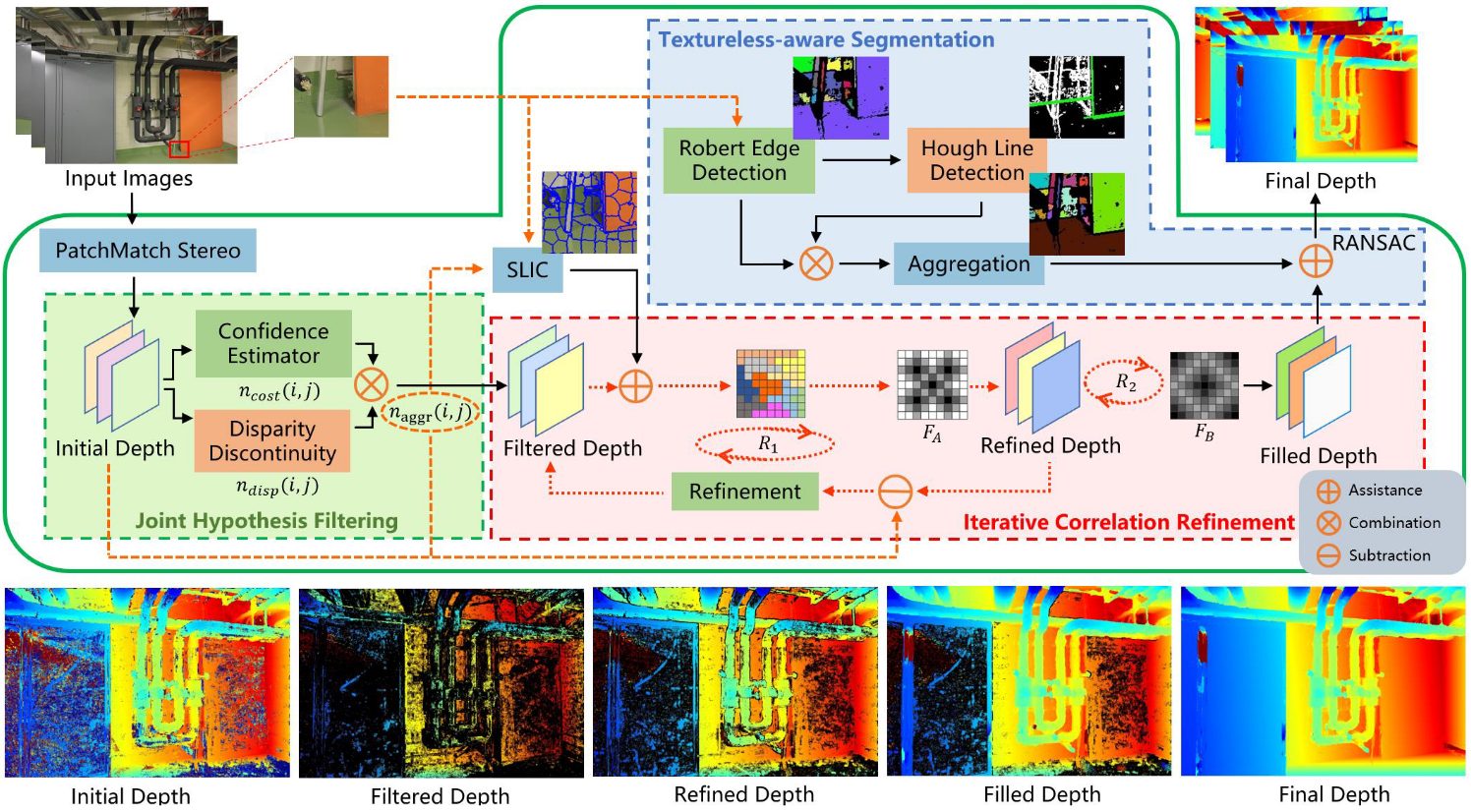
TSAR-MVS: Textureless-aware segmentation and correlative refinement guided multi-view stereo
Yuan Z., Cao, J., Wang, Z., Li, Z..
Pattern Recognition (PR), 2024.
📖 All Publications
ICLR 2025Video-STAR: Reinforcing Zero-shot Video Understanding with Tools. Z Yuan, X Qu, C Qian, et al.ICLR 2025AutoDrive-R2: Incentivizing Reasoning and Self-Reflection Capacity for VLA Model in Autonomous Driving. Z Yuan, J Tang, J Luo, et al.PreprintWhat if Agents Could Imagine? Reinforcing Open-Vocabulary HOI Comprehension through Generation. Z Yuan, X Qu, J Tang, et al.PreprintFrom Scale to Speed: Adaptive Test-Time Scaling for Image Editing. X Qu, Z Yuan, et al.PreprintRecovering Degradations with Generative Model: A Consistency-aware Distillation Network for Infrared and Visible Image Fusion. H Yu, Z Yuan, Y Bai, et al.PreprintPure Vision Language Action (VLA) Models: A Comprehensive Survey. D Zhang, J Sun, C Hu, X Wu, Z Yuan, et al.PreprintAT-Drive: Exploiting Adversarial Transfer for End-to-end Autonomous Driving. D Zhang, Z Yuan, K Huang, et al.PreprintADDI: A Simplified E2E Autonomous Driving Model with Distinct Experts and Implicit Interactions. D Zhang, Z Yuan, Chen Y., et al.IEEE JBHI 2025EMPOWER: Evolutionary Medical Prompt Optimization With Reinforcement Learning. Y Chen, Y He, J Yang, D Zhang, Z Yuan, et al.IEEE TCSVT 2025DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo. Z Yuan, D Zhang, Z Li, et al.NIPS 2025InstructHOI: Context-Aware Instruction for Multi-Modal Reasoning in Human-Object Interaction Detection. J Luo, W Ren , Q Zheng, Y Zhang, Z Yuan, et al.IEEE TCSVT 2025Learning multi-view stereo with geometry-aware prior. K Chen, Z Yuan, H Xiao, T Mao, et al.HCII 2025MR-IntelliAssist: A World Cognition Agent Enabling Adaptive Human-AI Symbiosis in Industry 4.0., C Liu, Z Yuan, Y Wang, Y Yin, et al.IEEE TCSVT 2025SED-MVS: Segmentation-Driven and Edge-Aligned Deformation Multi-View Stereo with Depth Restoration and Occlusion Constraint., Z Yuan, Z Yang, Y Cai, et al.AAAI 2025Dual-level precision edges guided multi-view stereo with accurate planarization., K Chen, Z Yuan, T Mao, et al.AAAI 2025Mapexpert: Online hd map construction with simple and efficient sparse map element expert., D Zhang, D Chen, P Zhi, Y Chen, Z Yuan, et al.AAAI 2025DVP-MVS: Synergize depth-edge and visibility prior for multi-view stereo., Z Yuan, J Luo, F Shen, et al.AAAI 2025MSP-MVS: Multi-granularity segmentation prior guided multi-view stereo., Z Yuan, C Liu, F Shen, et al.IEEE TCSVT 2025Light4gs: Lightweight compact 4d gaussian splatting generation via context model., M Liu, Q Yang, H Huang, W Huang, Z Yuan, et al.PreprintAdaptive label correction for robust medical image segmentation with noisy labels., C Qian, K Han, J Ding, L Liu, C Lyu, Z Yuan, et al.PreprintDyncim: Dynamic curriculum for imbalanced multimodal learning., C Qian, K Han, J Wang, Z Yuan, et al.PR 2025Nerf-based polarimetric multi-view stereo., J Cao, Z Yuan, T Mao, et al.PR 2024Tsar-mvs: Textureless-aware segmentation and correlative refinement guided multi-view stereo., Z Yuan, J Cao, Z Wang, et al.AAAI 2024Sd-mvs: Segmentation-driven deformation multi-view stereo with spherical refinement and em optimization., Z Yuan, J Cao, Z Li, et al.
🏆 Service
- Conference Reviewers: NeurIPS, ICML, ICLR, CVPR, ICCV, ECCV, AAAI
- Journal Reviewers: IJCV, TIP, TMM, TNNLS, TCSVT, PR